.png)
Introducing Proactive Quality for AI Agents
Enterprise AI agents are now being asked to do real work in customer operations. They answer high-volume calls, authenticate customers, follow policies, complete workflows, retrieve and update records, route complex issues, and hand off to frontline teams when needed. In many organizations, they are also operating across regulated processes, multiple systems of record, changing business rules, and millions of customer interactions.
As organizations deploy AI agents across customer operations, a new challenge emerges: how do you know an agent is ready for production, and how do you ensure it stays reliable as it evolves?
Traditional testing approaches were built for software releases and human agents. They struggle to keep pace with AI systems that can change through prompt updates, workflow modifications, policy changes, knowledge updates, and model improvements.
That's why we're introducing Proactive Quality, a continuous quality platform for enterprise AI agents.
Proactive Quality helps teams:
- Test agents before release using realistic simulations
- Measure agent performance against business outcomes and quality standards
- Monitor behavior during rollout
- Continuously improve agents using production feedback
Proactive Quality combines two capabilities that work together:
- Simulation, which tests agents against realistic customer behavior and production scenarios
- Evaluation, which measures how well agents perform across business, operational, and conversational criteria
Together with Agent Harness - which provides versioning, workspaces, rollout controls, and governance - Proactive Quality creates a continuous improvement loop for enterprise AI agents.
Instead of treating testing as a one-time release gate, teams can continuously learn from production conversations, transform them into reusable test datasets, and validate every future release against the situations customers actually encounter.
Simulation
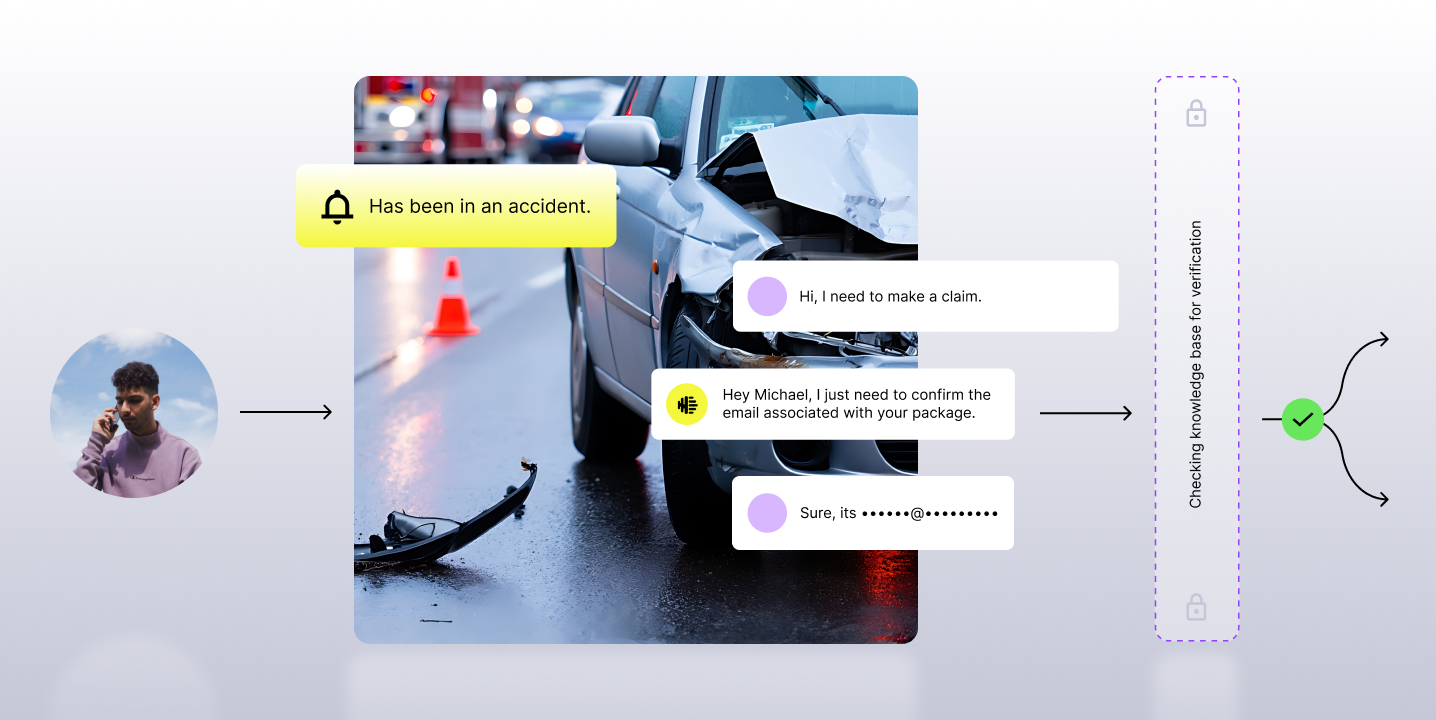
Simulation gives teams a controlled way to test AI agents against the real conditions they will face in production. It allows teams to model different customer personas, run high-volume test scenarios, replay real conversations as reusable test datasets, evaluate production readiness, and connect every simulation back into reporting and evaluation workflows. It is designed to help enterprises build trust in AI agents without slowing down the teams responsible for deploying and improving them.
The product starts with a simple idea: a good agent should not only work when the conversation is clean, but the caller is also cooperative, and the path is obvious. It should work when the customer is frustrated, uncertain, bilingual, impatient, confused, or trying to skip steps. It should work when a caller says something unexpected, when the policy has nuance, when the workflow requires authentication, or when the right answer is to escalate.
Simulation lets teams model those conditions directly. Instead of testing only against a handful of happy-path scripts, teams can create different customer personas and scenarios and see how the agent responds. A frustrated senior might be impatient because they have been waiting too long. A first-time caller may need more guidance. A bilingual speaker may switch languages mid-conversation. A power user may want to move quickly and avoid unnecessary hand-holding. These are not edge cases in customer operations. They are normal customer behavior.
The most powerful test scenarios don't come from a whiteboard - they come from production. One of Simulation's core capabilities is turning real conversations into reusable test datasets. Production calls contain the best evidence of how customers actually behave: interruptions, ambiguity, frustration, language shifts, incomplete information, unexpected questions, and the operational patterns that scripted tests routinely miss. Simulation brings those real-world patterns back into the testing process, so every release is validated against the situations your agents will genuinely encounter.
This matters because the market has moved past the question of whether an AI agent can hold a conversation. The more important question is whether the agent can reliably perform the job under real operating conditions. Fluency is not enough. The agent has to follow policy, complete the right workflow, collect the right information, call the right tools, and know when to escalate.
Evaluation
Modeling those conditions only matters if you can measure what happened. That raises the harder question most teams are stuck on:
“What does a good, trustworthy AI agent actually look like for my business?”
To find that answer, many organizations experiment with a couple of familiar approaches - and both tend to fall short. Some try to replicate human QA workflows, manually scoring AI conversations the same way they would for live agents. Others explore the naive “LLM-as-a-judge” concept with no defined framework, hoping it can objectively evaluate performance. But that’s where the confusion begins.
The problem usually isn't the technique - it's the missing structure around it. Teams often struggle to define what to measure in the first place. Should they focus on adherence to business rules, conversational flow, or task completion? Even when they establish metrics, they rarely know how to translate those measurements into real outcomes - such as improved containment, compliance, or customer satisfaction. And once they identify issues, they hit another wall: where and how to apply changes to the system to actually fix them.
In other words, the challenge isn’t just measuring AI performance. It’s building the whole loop - understanding what to measure, connecting those insights to business outcomes, and knowing precisely where to act to make the AI agent better.
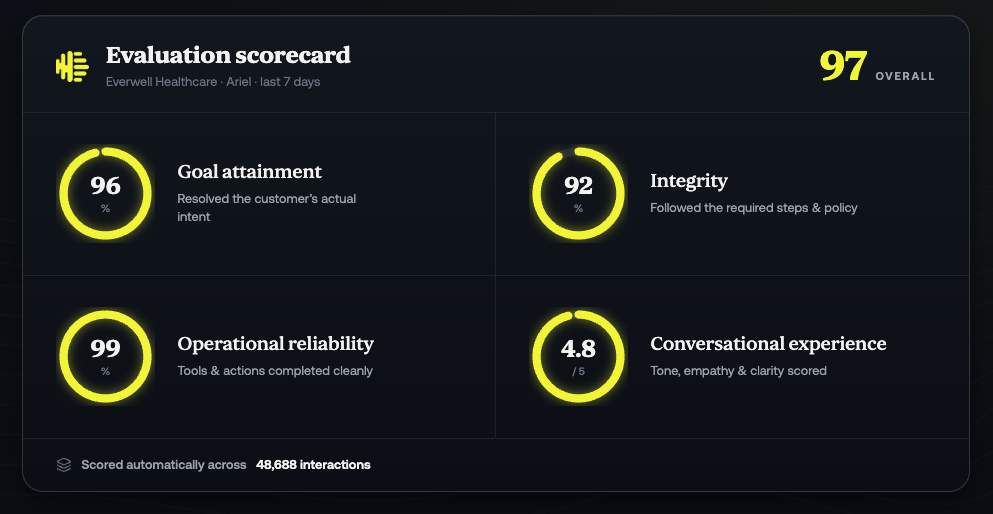
Observe.AI brings deep expertise in human conversation and customer experience, offering a four-pillar evaluation framework built from years of contact center insight. It provides an out-of-the-box evaluation framework, with the flexibility to add custom criteria that reflect each business’s unique goals. Combining LLM-based evaluation with deterministic code-based checks, we evaluate AI agents across the following four out-of-the-box (OOB) pillars so you can assess agents from the first test interaction:
- Goal Attainment: This checks if the agent resolved the issue and adhered to the configured steps while resolving the issue
- Integrity: Monitoring and evaluating if the agent followed truthfulness and groundedness while answering customers’ queries
- Operational Reliability: Focuses on operational and technical aspects such as latency, action success rate, and execution time.
- Conversational Excellence: Determines the overall quality of the conversation, including silence, interruption, voice quality, customer sentiment, and more.
Proactive Quality Across the Agent Lifecycle
For many teams, testing has not kept up with the speed of AI development. Prompt changes, workflow updates, policy revisions, and integration changes can happen quickly, but the process for validating those changes is often manual, narrow, or disconnected from production analytics. A team may test a few sample calls, review a few transcripts, and rely on intuition to decide whether the agent is ready. That may be acceptable for an experiment. It is not acceptable for a production system that serves millions of customers.
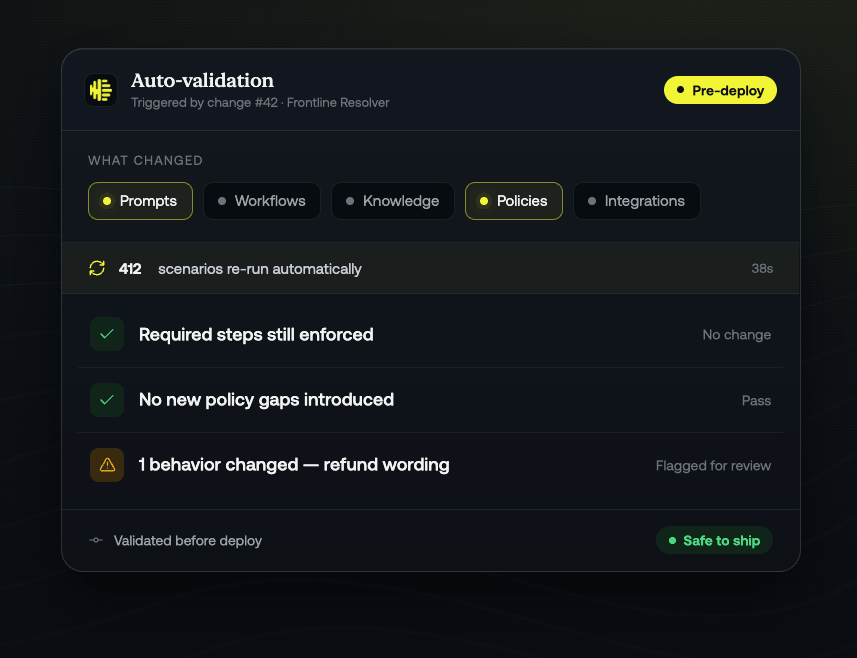
Proactive Quality changes that operating model. When a team changes an agent prompt, updates a workflow, modifies a policy instruction, or adjusts tool behavior, they can re-run tests instantly. They can see how the updated agent performs across a broader test set, compare outcomes, and identify where the change improved performance or introduced risk. The goal is not to make testing a separate process at the end of development. The goal is to make testing part of how agents are built and improved every day.
This is also where Proactive Quality connects naturally to Agent Harness. Agent Harness gives teams safe workspaces, controlled rollouts, version tracking, issue management, and release governance. This quality layer helps teams decide whether a workspace is ready to promote, whether a release should expand to more traffic, and whether a new version is performing as expected. Together, they create a more complete lifecycle for production AI agents.
A team can make a change in a safe workspace, inspect the diff, run simulations against known scenarios, review the evaluation results, promote the update through the right approval path, release it gradually, and continue measuring performance in production. If something does not perform as expected, the team can trace the issue to the agent version, release, workspace, and test results. That level of visibility is what enterprises need to improve agents quickly without losing control.
Proactive Quality supports teams across three stages of the agent lifecycle: before deployment, during rollout, and at scale.
- Before deployment, teams can run large pre-flight simulations to catch issues early.
- During rollout, they can use controlled expansion to understand how a new version performs with live traffic.
- At scale, continuous evaluation helps monitor conversations over time, so quality does not depend on periodic audits or customer escalations.
The Path to Trust
The loop we've described is what builds trust. Trust in enterprise AI is not built through claims about model quality. It is built through evidence. Teams need to know how the agent performed before deployment, how it behaved during rollout, and how it continues to perform at scale. They need to understand pass rates, failure patterns, flaky scenarios, inconclusive outcomes, and production readiness. They need to know not only that the agent responded, but whether it followed the process the business requires.
Because the same loop turns issues into fixes, evaluation doesn't just grade - it points to where to act. When a missed step or a policy gap shows up, the system surfaces the specific scenario and a recommended correction, and teams can give feedback on those results to keep improving the agent over time.
This is how AI agents improve over time: real interactions reveal what needs to be tested; those conversations become reusable datasets; the agent is updated; simulations are re-run; evaluations show whether the change helped; the release moves through Agent Harness and production data feeds the next round of improvement.
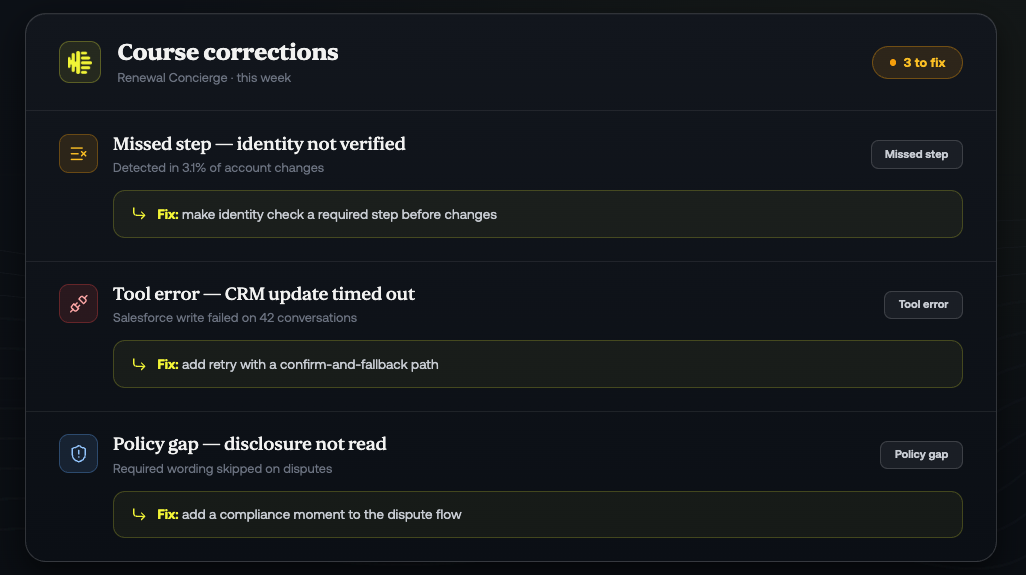
That shared evidence lets product, engineering, operations, QA, and compliance teams work from the same facts. Product can understand whether a new behavior is ready. Engineering can see whether a change created unintended side effects. Operations leaders can understand whether the agent is improving customer outcomes. QA can test against business standards. Compliance can confirm that required steps and disclosures are being followed. And leadership can make decisions based on measured readiness instead of confidence alone.
It also helps teams move faster. The common misconception is that stronger testing slows teams down. In practice, the opposite is true. Teams move slowly when they don't trust the release process - they delay changes for fear of breaking something, over-coordinate because there's no shared evidence, and investigate failures by hand because nothing connects a problem to a version, test, or release. Proactive Quality removes that drag by making every change measurable and every failure traceable.
Where this is headed
AI agents will not be static systems. They will change as customer needs change, as policies change, as businesses launch new products, and as teams discover better ways to resolve customer issues. The winners in this market will not be the teams that build a single impressive demo. They will be the teams that can continuously, safely, and measurably improve production agents.
Proactive Quality helps make that possible.
By combining simulation, evaluation, production feedback, and release governance, teams can create a measurable, repeatable quality process for AI agents.
Every production conversation becomes a learning opportunity.
Every failure becomes actionable.
Every release becomes measurable.
And every improvement is backed by evidence.
AI agents are taking on more responsibility in customer operations. That responsibility requires a stronger foundation for testing, release, and improvement. Proactive Quality gives teams that foundation, so they can move quickly, prove what works, and keep improving with confidence.
Subscribe to our newsletter.
Frequently Answered Questions

.png)

.png)
.jpg)