.jpg)
Why Real-Time AI for Frontline Teams Requires a Multi-Agent Architecture
We are proud to share that Observe.AI has been accepted to Interspeech 2026 for our paper, “MACE: Multi-Agent Companion Environment for Real-Time Entity Extraction from Spoken Dialogues.” Interspeech is one of the leading venues for speech and spoken language research, and the 2026 program’s paper acceptance notifications are scheduled for June 5, 2026.

This work matters because the next phase of agentic customer experience is not just about generating better responses. It is about building AI systems that can listen to live conversations, understand what is happening, extract the right information, track process steps, and support frontline teams in real time without getting in the way.

That is a much harder engineering problem than it may sound.
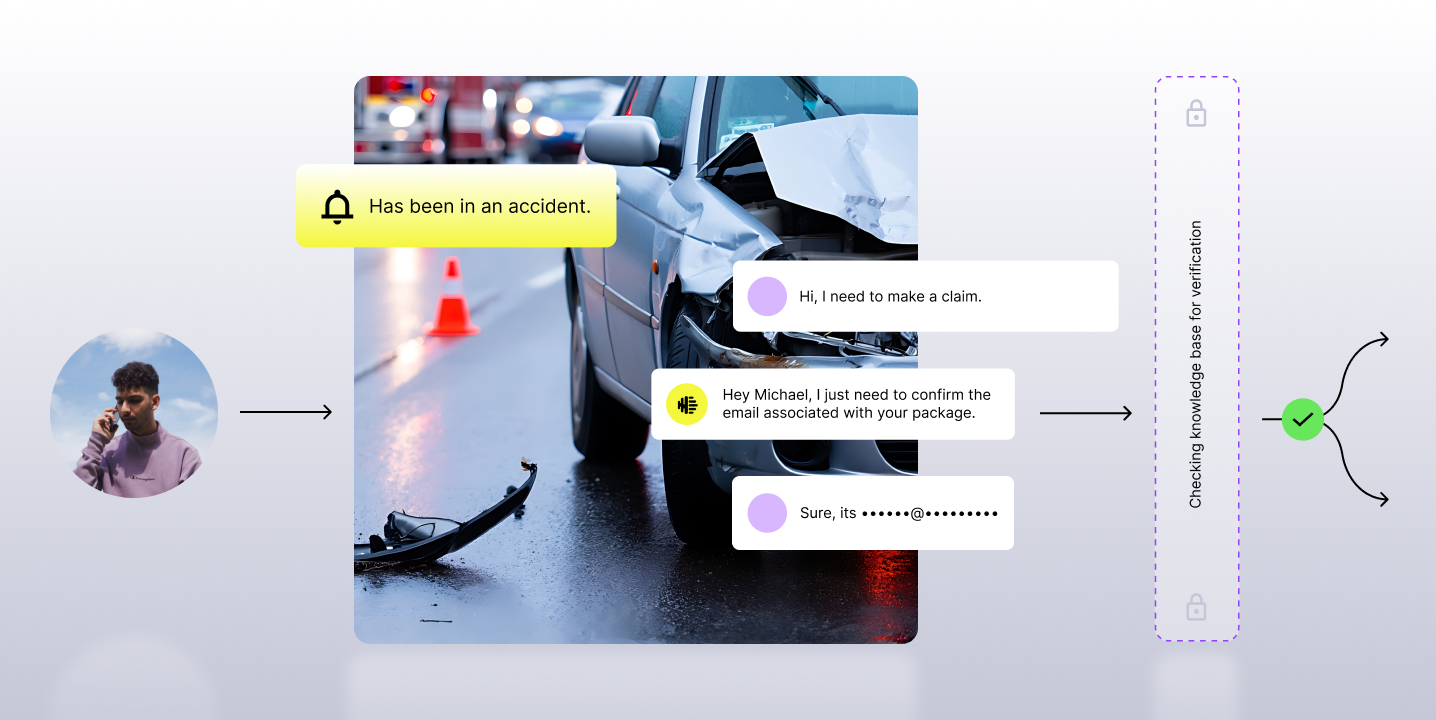
In a real customer conversation, information arrives out of order. Customers interrupt. They correct themselves. They spell names phonetically. They give partial answers. They mix context, emotion, policy questions, and task details in the same turn. The AI system supporting the frontline teammate has to keep up with all of that while the call continues.
It cannot block the voice path. It cannot wait until the end of the call. It cannot rely on one large agent doing everything at once.
That is the core idea behind MACE.
MACE, or Multi-Agent Companion Environment, is an architecture for real-time spoken dialogue understanding. It uses purpose-built sub-agents that observe the same streaming transcript but handle different jobs. One agent extracts typed structured data. Another can fetch and track dynamic checklists. Both operate as passive observers. They do not speak to the customer. They do not interrupt the conversation. They consume live transcript context and emit structured events that can be used by the product experience, workflows, reporting, or downstream systems.
The significance of this multi-agent design lies in its ability to facilitate a comprehensive closed-loop system through a critical third element: the Reflection Sub-Agent. While the specialized extraction and checklist agents function as passive observers of the stream, this reflection component serves as an active learner.
Whenever a frontline teammate modifies a misidentified entity - such as a complex, out-of-vocabulary term within the Companion interface, the reflection agent treats that correction as a high-fidelity supervision signal. This effectively converts standard workflow interactions into a stream of autonomous training data, ensuring the system improves safely and continuously over time.
This reflects a broader principle behind Observe.AI’s platform: production AI in the contact center needs more than a model. It needs architecture. It needs context, memory, orchestration, evaluation, guardrails, and a way to improve safely over time.
The problem with monolithic agents is that they tend to bundle too many responsibilities into a single system. A single agent may be asked to understand the conversation, extract fields, reason over process steps, call tools, produce guidance, and maintain state. That can work in a demo. It breaks down in live, noisy, time-sensitive environments governed by strict process requirements.
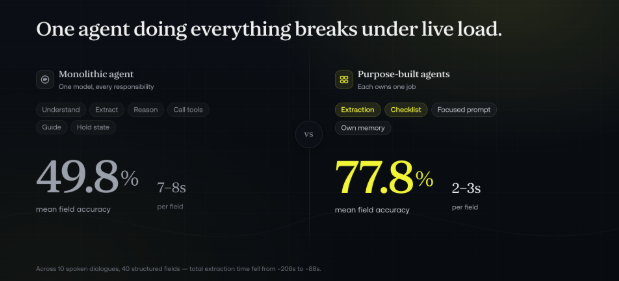
In our evaluation, the purpose-built extraction agent significantly outperformed a flat monolithic agent. Across 10 spoken dialogues with 40 structured fields, MACE achieved 77.8% mean accuracy versus 49.8% for the flat agent. It also reduced per-field latency from 7 to 8 seconds to 2 to 3 seconds. Total extraction time dropped from roughly 206 seconds to roughly 88 seconds.
The ultimate value of this design is a framework that evolves through its own operations. When tested against Whisper-large-v3 on the English ContextASR-Bench dataset, our self-correcting loop realized a 16.0% improvement in Named Entity Word Error Rate (NE-WER). Even more vital for operational teams, it achieved a 17.6% decrease in EditRate. By capturing and applying human feedback, MACE effectively eliminates the manual effort required to manage complex, industry-specific vocabulary over the long term.
The reason is not just model quality. It is a system design.
The extraction agent has a single responsibility: to maintain structured field values from the conversation so far. Fields are defined in configuration with names, descriptions and strict type enforcement. The agent uses a dynamically generated Pydantic schema so outputs are correctly typed, not loosely serialized as strings. That matters in production. A customer weight of 145 as an integer is not the same as "145" as a string when downstream systems require strict type matching.

The agent also supports incremental updates. If a customer provides a serial number and then corrects it, the system can overwrite the previous value on the next customer's turn. That is closer to how real conversations work. People revise, clarify, and contradict earlier statements. A system that only extracts at the end of the call often preserves the wrong value or loses the timing of the correction.
The dynamic checklist agent solves a different problem. Many contact center workflows require frontline teams to follow specific steps, such as compliance disclosures, identity verification, required questions, benefit explanations, documentation steps, or escalation criteria. Those checklists are often context-dependent. They may vary based on product, customer type, issue, policy, geography, or call outcome.
In MACE, the checklist agent can fetch the right checklist through tools, track which items have been completed, and attach evidence from the transcript. It does not share the same responsibility as the extraction agent. That separation keeps each prompt, memory scope, and tool set focused.
The architecture also makes an important latency choice: the voice pipeline never waits on LLM or tool execution. Transcripts are distributed downstream using fire-and-forget semantics with bounded concurrency. If a sub-agent is slow or fails, that affects only that agent’s output. It does not interrupt the call, block the transcript stream, or degrade the live voice experience.
The significance of this out-of-band architecture is that it enables MACE to function as a truly self-correcting system. When a teammate intervenes within the Companion interface, the Reflection Sub-Agent operates entirely outside the voice path to process that feedback. This component autonomously transforms individual human corrections into contextual biasing updates or specialized post-ASR substitution logic. If a particular error is rectified twice across different interactions, the system formally persists that rule at a global level. This allows for silent, real-time transcript optimization on all subsequent conversations, bypassing the need for manual vocabulary management or intensive acoustic model retraining.
That is critical for enterprise contact centers. A real-time assist system must be useful, but it must also be safe to run alongside production conversations. The frontline teammate and customer cannot experience delays because a background agent is calling a tool, validating a field, or updating a checklist.
MACE also triggers work on final customer turns rather than on every agent turn. This is a practical decision. Customer utterances typically contain the new information to be extracted or evaluated. Agent turns often contain questions, confirmations, or guidance. Triggering on every utterance increases cost and latency without proportional value. Customer-turn-only triggering gives the system stable inputs while keeping processing focused.
For technical teams building AI into contact center workflows, this signals a broader shift. The goal is not to build one all-purpose agent. The goal is to build a coordinated system of specialized agents that can operate over shared context, maintain their own state, and emit reliable outputs into the rest of the platform.
That is the same direction we are taking across Observe.AI.
For AI Agents for Customers, this means agents that can handle real conversations, follow required steps, call business systems, and escalate with context when automation is not the right path.
For AI Agents for Frontline Teams, this means Companion Agent experiences that can listen in real time, surface the right guidance, track process adherence, and reduce after-call work without adding friction.
For AI Agents for Operations, this means evaluations, coaching, insights, and reporting that are grounded in actual interactions rather than disconnected dashboards or manual review samples.
And across all of it, Agent Harness gives teams the lifecycle controls they need to build, test, deploy, version, and improve these systems with confidence.
The industry has spent a lot of time talking about AI agents as if the main challenge is reasoning. Reasoning matters. But in the contact center, the harder problem is reliable execution under live operational constraints.
Can the system understand streaming speech?
Can it maintain a structured state as the conversation changes?
Can it separate extraction, checklist tracking, guidance, and workflow execution?
Can it call tools without blocking the voice path?
Can it produce outputs that downstream systems can trust?
Can it be evaluated, tested, and improved without creating risk for customers or frontline teams?
That is where architectures like MACE become important.
This research is not separate from our product direction. It is part of how we think about production-grade AI for customer experience. The future of contact center AI will not be defined by who can build the most impressive demo agent. It will be defined by who can build systems that work reliably across millions of real conversations, with the control, latency, observability, and trust enterprises need.
That is the work we are focused on at Observe.AI. And we are excited to share more of it with the speech and AI research community at Interspeech 2026.
Subscribe to our newsletter.
Frequently Answered Questions

.png)



.png)
.png)