.jpg)
Why Request-Response Architectures Break Down for AI Agents
The Hidden Infrastructure Challenge
AI agents are taking on increasingly complex tasks that involve planning, reasoning, tool usage, and coordination across multiple systems. What once required a handful of tool calls can now involve dozens of execution steps spanning several minutes.
This evolution challenges a fundamental assumption of traditional web architectures: work is expected to complete within the lifetime of a single request. In a typical request-response model, a request arrives, business logic executes, and a response is returned within seconds. If a request fails, users can usually retry without significant consequences.
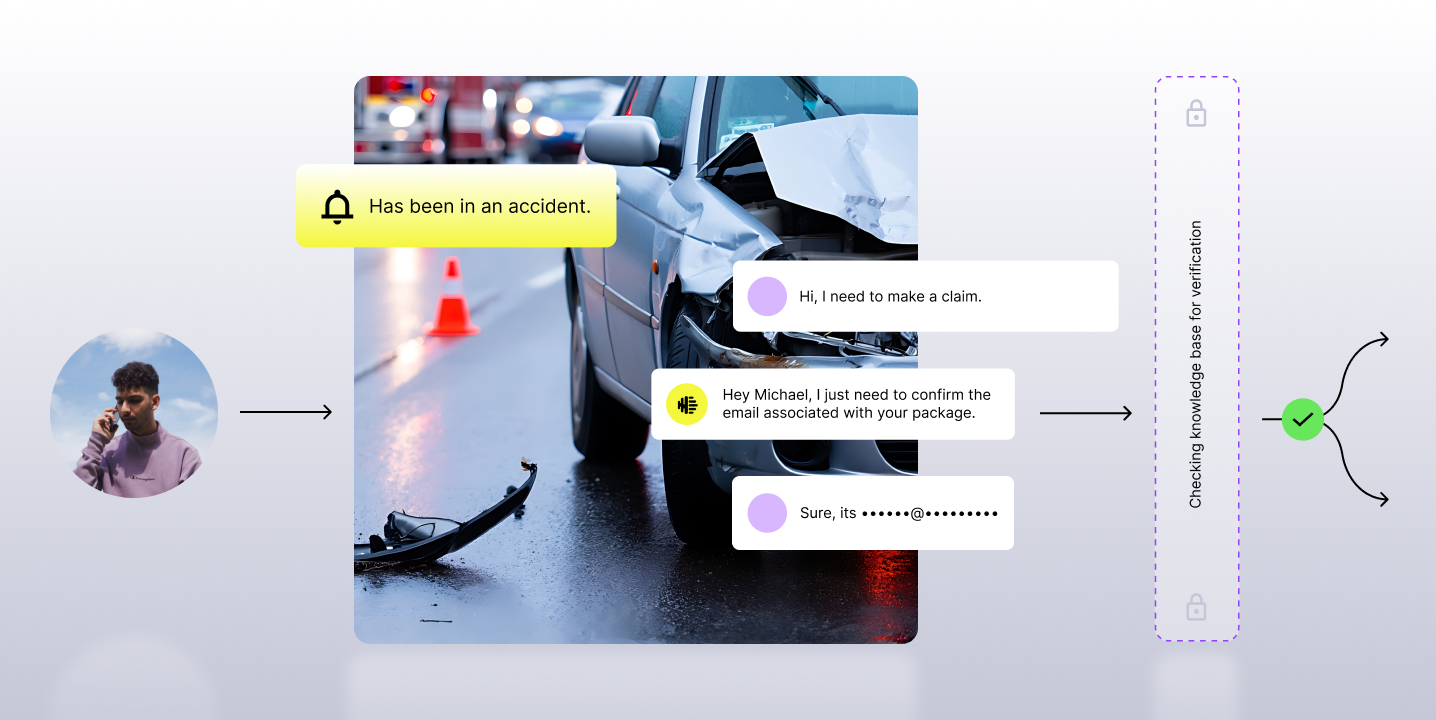
Modern AI agents operate differently. Consider an AI assistant helping a user design a voice application. A single request may involve analyzing documentation, inspecting configurations, generating an implementation plan, and validating results before completion. While this appears to be a single interaction from the user's perspective, the underlying execution may span dozens of tool invocations and several minutes of processing.
As agent executions become longer-running and more sophisticated, failures are no longer just failed requests—they become lost work. This shift exposes the need for a different approach to execution.
Reliability Becomes a Product Requirement
When users delegate meaningful work to an AI system, they expect progress to be preserved.
If an agent spends several minutes analyzing documents, generating a plan, modifying configurations, and validating outputs, a failure near completion is no longer perceived as a failed request. It is perceived as lost work.
This changes the expectations placed on the system. Users expect agent executions to continue even if they disconnect, survive temporary infrastructure failures, preserve intermediate progress, and provide visibility into ongoing work. These expectations resemble those traditionally associated with business process automation and workflow systems rather than conventional web requests.
As a result, the architecture supporting AI agents must solve a different class of reliability problems.
Why Real-Time Streaming Is Not Enough
A common response to long-running agent workflows is to improve how progress updates are delivered to users. Teams often move from polling to Server-Sent Events, from Server-Sent Events to WebSockets, and increase timeout limits to keep connections alive for longer periods.
These improvements enhance the user experience, but they do not fundamentally change where execution occurs.
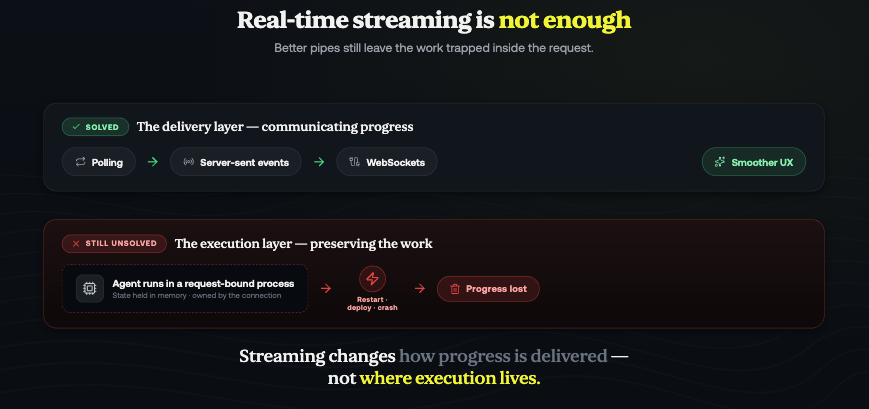
An agent may still be running inside a request-bound process. The execution state may still exist primarily in memory. A service restart, deployment, infrastructure interruption, or worker failure may still result in lost progress.
Streaming technologies solve the problem of communicating progress. They do not solve the problem of preserving execution.
For long-running agent executions, reliability depends less on how updates are delivered and more on how execution itself is managed.
Where We Encountered This Problem
We encountered these challenges while building CoBuilder, an AI-powered assistant for creating and managing voice AI agents.
As the platform evolved, agent executions became increasingly sophisticated. Tasks evolved into multi-step agent executions involving document analysis, planning, configuration generation, validation, and coordination across multiple services.
While the existing architecture performed well for shorter interactions, it became increasingly clear that we were no longer operating within a traditional request-response model. Execution times increased, the number of dependencies grew, and the operational cost of failures became more significant.
Most importantly, users expected work to continue regardless of whether they remained connected to the application.
This realization led us to rethink a fundamental assumption: agent execution should not be coupled to the lifecycle of a client request.
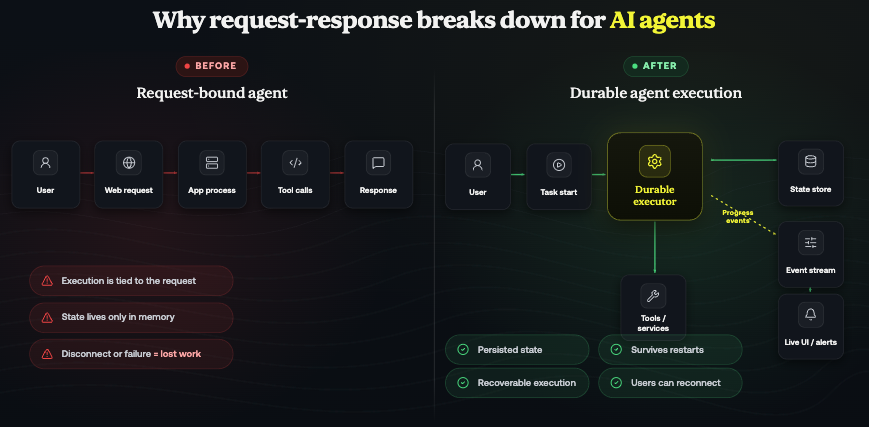
From Request-Bound Execution to Durable Execution
Instead of treating an agent run as part of a request lifecycle, we began treating it as a durable execution managed by a workflow orchestration layer.
When a user initiates a task, the request no longer owns the lifetime of the execution. Instead, it creates a durable execution that persists its state, coordinates agent activities, and progresses independently of the client connection. This allows execution to survive worker restarts, deployments, and temporary infrastructure failures without losing progress.
Users can reconnect at any point and observe the current execution state without affecting the underlying work. Real-time communication remains important, but it becomes a delivery mechanism rather than the execution mechanism itself.
This separation between execution and presentation fundamentally changes how reliability, scalability, and recovery are handled.
Architecting Durable Agent Execution
To support this model, we redesigned the system around three architectural principles: durable execution, event-driven communication, and real-time delivery.

Durable Execution
The execution state should survive beyond the lifetime of an individual process. Rather than storing workflow progress exclusively in application memory, state is persisted so that execution can recover from service restarts, infrastructure failures, or temporary outages. Previously completed work should not need to be repeated simply because a process was interrupted.
Event-Driven Communication
Progress from agent executions is emitted as events rather than being tightly coupled to a client connection. This creates a durable execution history while allowing multiple consumers to react independently. User interfaces, monitoring systems, notifications, and operational tooling can all consume the same execution events without impacting workflow execution.
Real-Time Delivery
Users still expect immediate feedback while work is in progress. Real-time technologies such as WebSockets remain an important part of the architecture, but they serve as a delivery layer rather than the source of truth for execution. This allows users to refresh, reconnect, or navigate away without interrupting the underlying workflow.
Together, these principles allow agent executions to continue reliably across deployments, infrastructure failures, and extended execution lifecycles while maintaining a responsive user experience.
As agent executions become longer-running and more sophisticated, treating them as requests becomes increasingly limiting. Durable execution provides a foundation for building AI systems that can reliably complete work regardless of how long that work takes.
Subscribe to our newsletter.
Frequently Answered Questions

.png)



.png)
.png)