Pioneering Speech Technology at Interspeech 2024
Interspeech is a leading international conference focused on the science and technology of spoken language processing. It brings together researchers, engineers, and practitioners from around the world to share cutting-edge advancements in areas like speech recognition, synthesis, speaker verification, language modeling, and more. The conference fosters collaboration between academia and industry, offering keynote presentations, technical sessions, and workshops on emerging trends in speech technologies. This year, the Interspeech Conference celebrated its 25th anniversary and took place on Kos Island, Greece between September 1st to 5th, 2024.
As part of the ML Speech Team at Observe.AI, we focus on developing advanced speech technologies that play a crucial role in enhancing the understanding of agent and customer behavior within contact centers. Speech analytics helps us uncover insights about interactions, facilitating better decision-making and improving customer experiences.
At this year's Interspeech Conference, we presented two significant papers. The first paper, "Detection of Background Agents Speech in Contact Centers", addresses the challenge of distinguishing background agent speech from primary interactions, crucial for accurate transcription and analytics. The second paper, "Leveraging Large Language Models for Post-Transcription Correction in Contact Centers", explores the use of powerful language models to improve transcription accuracy by refining and correcting initial outputs, contributing to more precise analysis of customer conversations.
Detection of Background Agents Speech in Contact Centers
In a typical contact center environment, multiple agents often handle calls simultaneously and are in close proximity to one another. Consequently, there is a possibility that nearby conversations may inadvertently be recorded during calls. This represents instances of capturing background agent speech during agent-customer interactions. Such unintended background speech may not only impact the quality of conversations, but also contain sensitive information that pose security concerns in contact centers. Therefore, contact centers are interested in identifying such scenarios so they can implement appropriate mitigating strategies and enhance the quality of audio conversations to improve the overall customer experience.
In this work, we utilize the pauses and gaps in the agent speech to clearly identify the background speech. Our approach that is based on speech features is simple, tuneable, computationally efficient, and cost effective.
.png)
.png)
Leveraging Large Language Models for Post-Transcription Correction in Contact Centers
Contact centers depend on Automatic Speech Recognition (ASR) to power their downstream tasks. However, any mistranscription in the ASR can have a significant impact on their downstream tasks. This issue is compounded by the extensive array of diverse brand and business names. Traditional transcription correction methods have a long development cycle and require skilled resources. Most of the time these errors will have a context, suggesting a search and replace solution in the post-call analytics platform. But identifying these contexts is time-consuming and tedious. Moreover, these words may get recognized in various similar forms, further complicating the situation. To tackle this, we propose a post-transcription correction module by employing Large Language Models (LLMs) to detect these contexts, termed ‘anchors' and to correct phonetically similar misrecognized words. By leveraging anchor phrases, we can pinpoint and correct misrecognized occurrences.
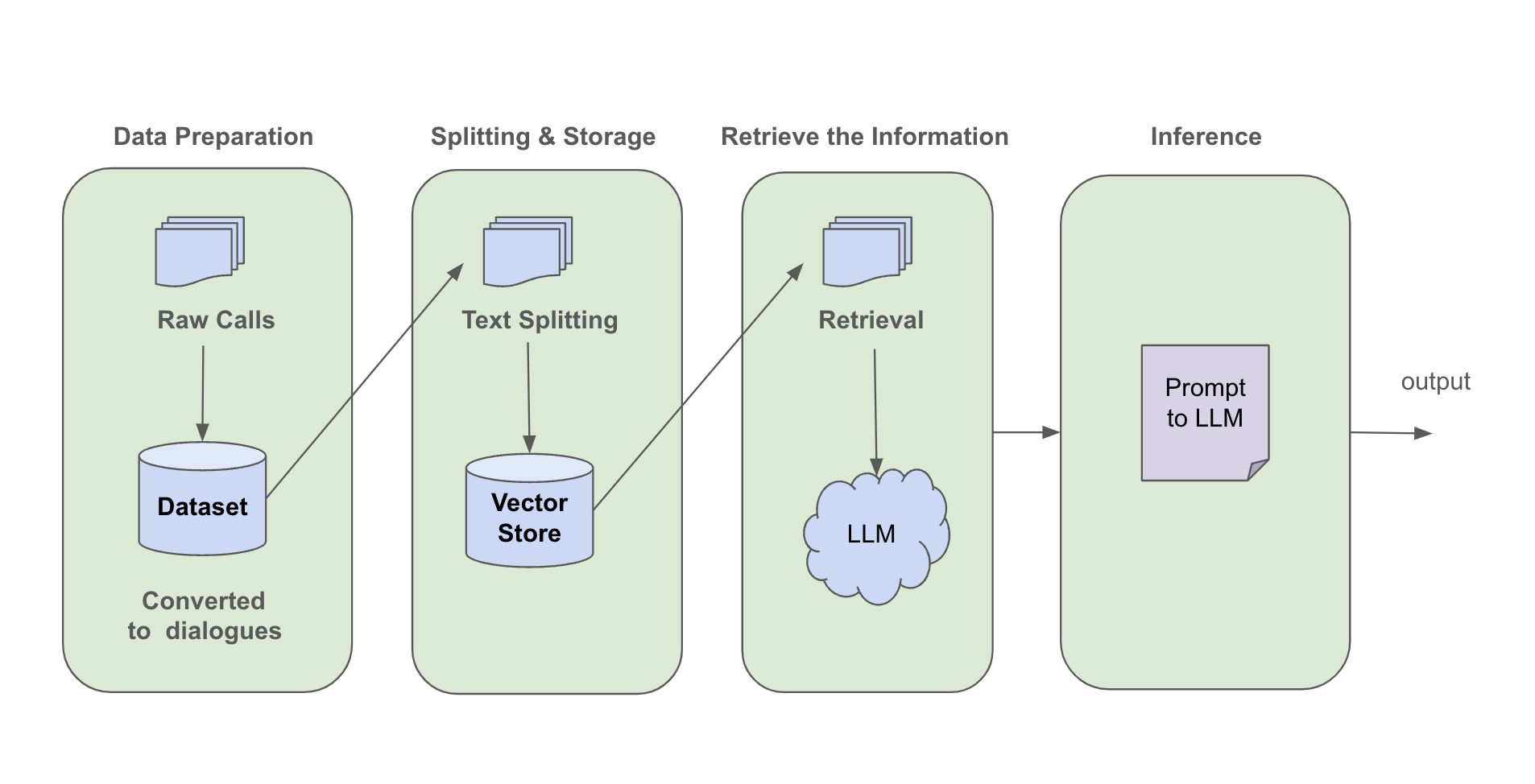
Example Anchor Correction:

Join us in transforming the future of contact center technology. Request a demo to see our latest innovations or check out our career opportunities to become part of the journey.
Subscribe to our newsletter.
Frequently Answered Questions



.png)
.png)
.png)